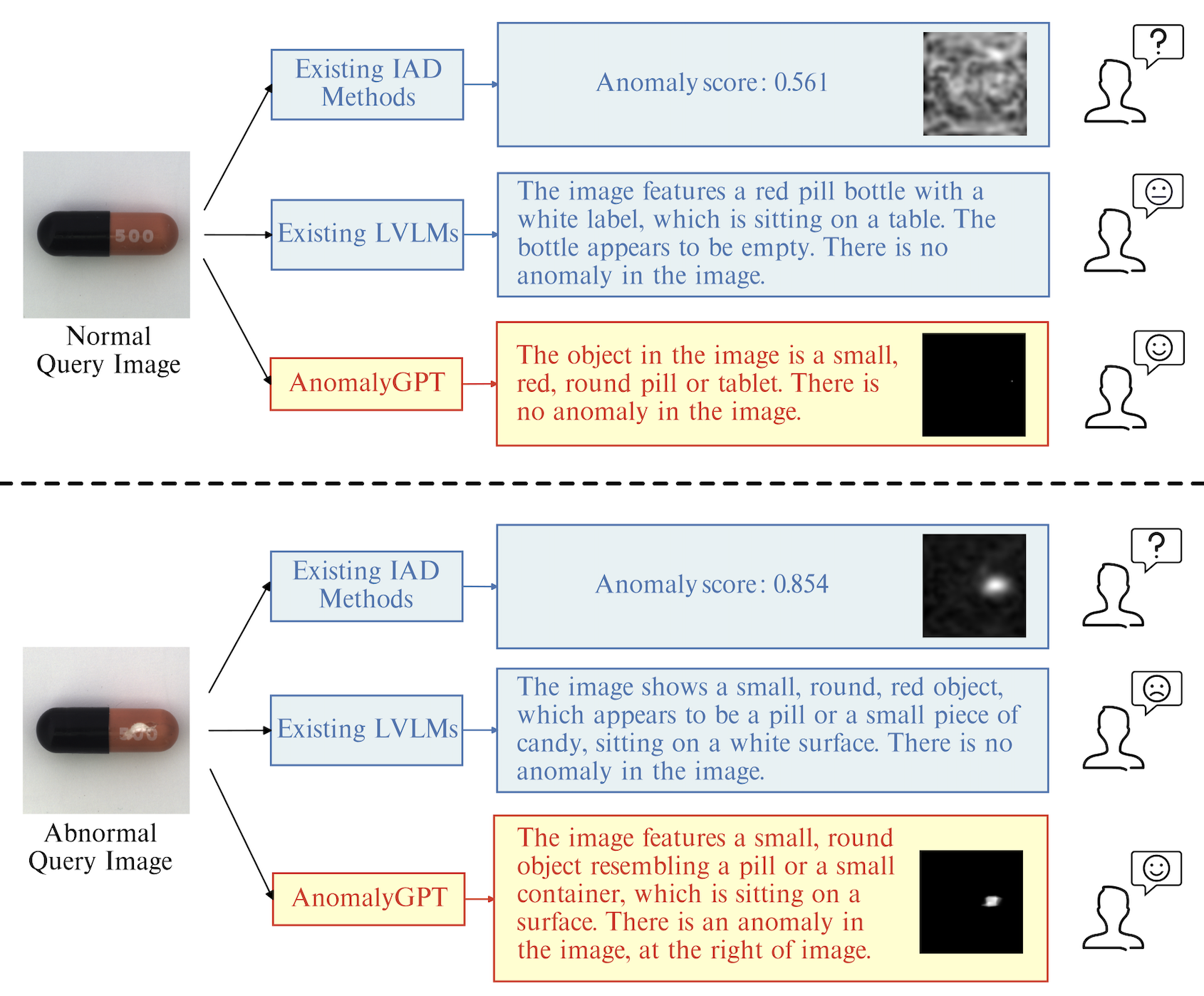
Large Vision-Language Models (LVLMs) such as MiniGPT-4 and LLaVA have demonstrated the capability of understanding images and achieved remarkable performance in various visual tasks. Despite their strong abilities in recognizing common objects due to extensive training datasets, they lack specific domain knowledge and have a weaker understanding of localized details within objects, which hinders their effectiveness in the Industrial Anomaly Detection (IAD) task. On the other hand, most existing IAD methods only provide anomaly scores and necessitate the manual setting of thresholds to distinguish between normal and abnormal samples, which restricts their practical implementation. In this paper, we explore the utilization of LVLM to address the IAD problem and propose AnomalyGPT, a novel IAD approach based on LVLM. We generate training data by simulating anomalous images and producing corresponding textual descriptions for each image. We also employ an image decoder to provide fine-grained semantic and design a prompt learner to fine-tune the LVLM using prompt embeddings. Our AnomalyGPT eliminates the need for manual threshold adjustments, thus directly assesses the presence and locations of anomalies. Additionally, AnomalyGPT supports multi-turn dialogues and exhibits impressive few-shot in-context learning capabilities. With only one normal shot, AnomalyGPT achieves the state-of-the-art performance with an accuracy of 86.1%, an image-level AUC of 94.1%, and a pixel-level AUC of 95.3% on the MVTec-AD dataset.