
A field of computer science, computer vision enables computers to identify patterns in visual content such as images and video. From inventory scanning robots to grab-and-go stores, computer vision is forecasted to revolutionize the retail industry. For example, automatic checkout technology (ACO) automatically generates shopping lists from images of products for purchase at brick-and-mortar stores, vastly improving the efficiency of traditional shopping experiences.
The main challenge of developing computer vision models for retail use cases comes from the difficulty of collecting sufficient training data to reflect realistic checkout scenarios. The following list contains publicly available retail image datasets for product and object recognition.
Retail Checkout Datasets / Automatic Checkout Datasets
Grocery Dataset: An image dataset contains 354 grocery images of ~40 groceries, captured with 4 cameras divided into 10 product categories.
Retail Product Checkout Dataset: The largest dataset in terms of both product image quantity and product categories containing single-product images and multi-product images taken by the checkout system alongside different levels of annotations for the checkout images.
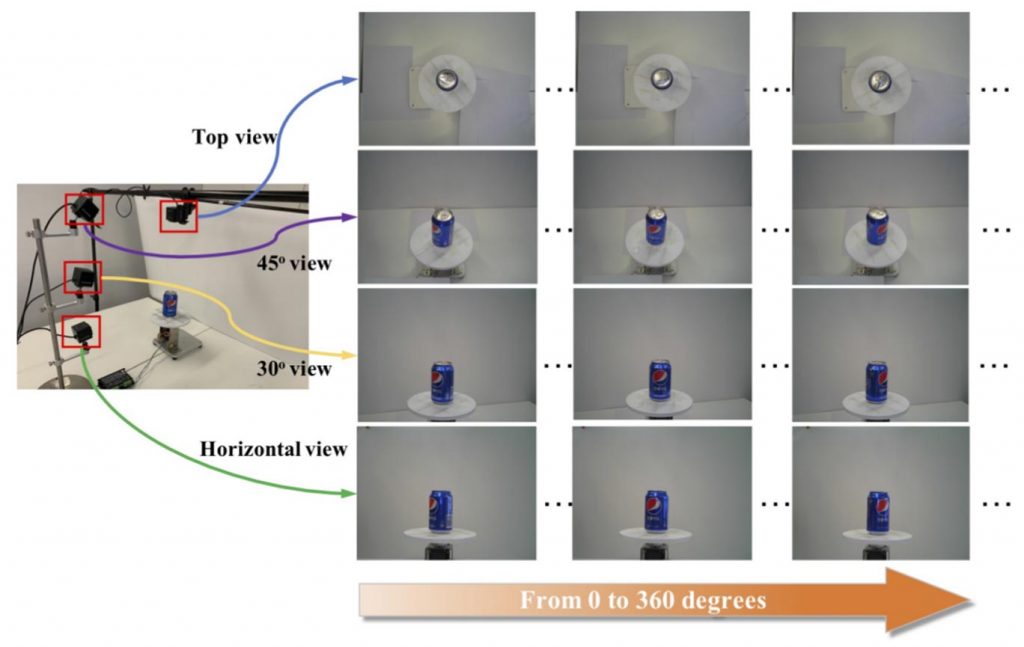
MVTec Densely Segmented Supermarket Dataset (MVTec D2S): It contains 21,000 high-resolution images with pixel-wise labels of all object instances. The objects comprise groceries and everyday products from 60 categories. The benchmark is designed such that it resembles the real-world setting of an automatic checkout, inventory, or warehouse system. The training images only contain objects of a single class on a homogeneous background, while the validation and test sets are much more complex and diverse.
The Freiburg Groceries Dataset: The Freiburg Groceries Dataset consists of 5000 256×256 RGB images of 25 food classes. Examples for each class can be found below.

Online Retail Datasets
Fashion-MNIST: A dataset of Zalando’s article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28×28 grayscale image, associated with a label from 10 classes.
COCO Dataset: The COCO dataset is an excellent object detection dataset with 80 classes, 80,000 training images and 40,000 validation images.
E-commerce Tagging for clothing: About 500 images from ecommerce sites with bounding boxes drawn around shirts, jackets, etc.
Product / Object Recognition Datasets
Food Image Datasets: Two food image datasets, 1) a dataset containing 2500 food and 2500 non-food images, for the task of food/non-food classification and 2) a dataset containing 16643 food images grouped in 11 major food categories.
Fruits 360 dataset: 65,429 images of 95 different fruits
Flowers Recognition: This dataset contains labeled 4242 images of flowers The data collection is based on the data flickr, google images, yandex images.
Boat types recognition: About 1,500 pictures of boats classified in 9 categories. You’ll find about 1,500 pictures of boats, of various sizes, but classified by those different types: buoy, cruise ship, ferry boat, freight boat, gondola, inflatable boat, kayak, paper boat, sailboat.
Stanford Cars Dataset: The Cars dataset contains 16,185 images of 196 classes of cars. The data is split into 8,144 training images and 8,041 testing images, where each class has been split roughly in a 50-50 split. Classes are typically at the level of Make, Model, Year, ex. 2012 Tesla Model S or 2012 BMW M3 coupe.
In case you missed our previous dataset compilations, you can find them all here. Still can’t find the custom data you need to train your model? Lionbridge AI provides machine learning data in dozens of languages for machine learning project needs.